ZooKeeper and Kafka
11 Apr 2019 • Leave CommentsZooKeeper ABCs
Kafka replies on and is the client of ZooKeeper.
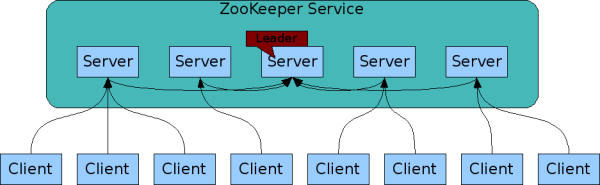
ZooKeeper is a Distributed Coordination Service for Distributed Applications (i.e. Kafka), relieving them from coordination but focusing on high-level synchronization, configuration maintenance, and groups and naming.
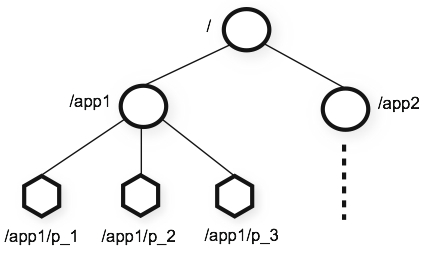
ZooKeeper defines a hierarchical namespace similar to the structure and a Linux filesystem like the figure below. Each node in the tree is named as a path starting with a forward slash '/' (the root node). In ZooKeeper parlance, a tree node is called znode.
As ZooKeeper is designed to coordinate data (like metadata, configuration, location etc.), so the data stored in each znode is usually small in the byte to kilobyte range. ZooKeeper keeps the data in memory for high throughput and low latency. Meanwhile, snapshots of the in-memory data is kept in a persistent storage (disk) along with transaction logs. Transaction logs refer to logs of clients' read and write operations.
Like the applications it coordinates, ZooKeeper itself is also distributed and replicated across a cluster of hosts - ZooKeeper ensemble. The in-memory data and persistent data are replicated among the ZooKeeper servers.
The servers that make up the ZooKeeper ensemble must all know about each other (by configuration file). ZooKeeper performs heartbeats test (a tiny packet) periodically to check connection and availability of servers.
At any give moment, a client (a coordinated application) connects (TCP connection) to a single ZooKeeper server, and switch to another one if the current TCP connection breaks. Read requests are served locally while requests to change the state of data (write requests) are all forwarded to a particular server called leader. The rest servers are called followers (similar to partitions leader and followers of Kafka). Followers replicate write results from the leader to keep synchronized.
Write synchronization is the core of ZooKeeper.
The underlying implementation takes care of replacing the leader upon failure and syncing followers with the leader.
Quorum
According to Wikipedia, a quorum is the minimum number of members of a deliberative assembly necessary to conduct the business of that group. A quorum requirement is protection against totally unrepresentative action in the name of the body by an unduly small number of persons. A quorum is often more than half of the total number.
ZooKeeper is functional only when a quorum of the servers are available. Recall that all writes requests are forwarded to the leader in ZooKeeper. Upon successive write, the result is synced to followers. If less than a quorum of the servers are synched on the write, ZooKeeper was nonfunctional as 'write synchronization is the core'.
Take 4 ZooKeeper servers for example, a quorum is 3 (> 4/2) which allows 1 server failure and writes should be synced among 3 servers. If there are only 3 servers, the quorum is 2 (> 3/2) which is able to allow 1 server failure as well. So the additional 4th server does not bring in any improvement in terms of stability. However, it benefits load balancing. But what if the number is increased to 5? This requires 3 (> 5/2) servers to form a quorum, the same as a 4-server ZooKeeper. However, the system allows 2 server failure and is more fault-tolerant. Usually, either 3 or 5, not 4 - choose an odd number, namely 1, 3, 5, etc.
ZooKeeper elects the leader from at least of a quorum of the servers. Therefore, proper choice of the number of servers is essential for deployment. If there is only 1 server, it forms the standalone mode, otherwise, it is replicated mode.
A basic rule:
- At least a quorum of ZooKeeper servers are online (active);
- At least a quorum of active ZooKeeper servers are synched on a 'write' operation.
Read more about quorum at why-zookeeper-on-odd-number-nodes?
Kafka ABCs
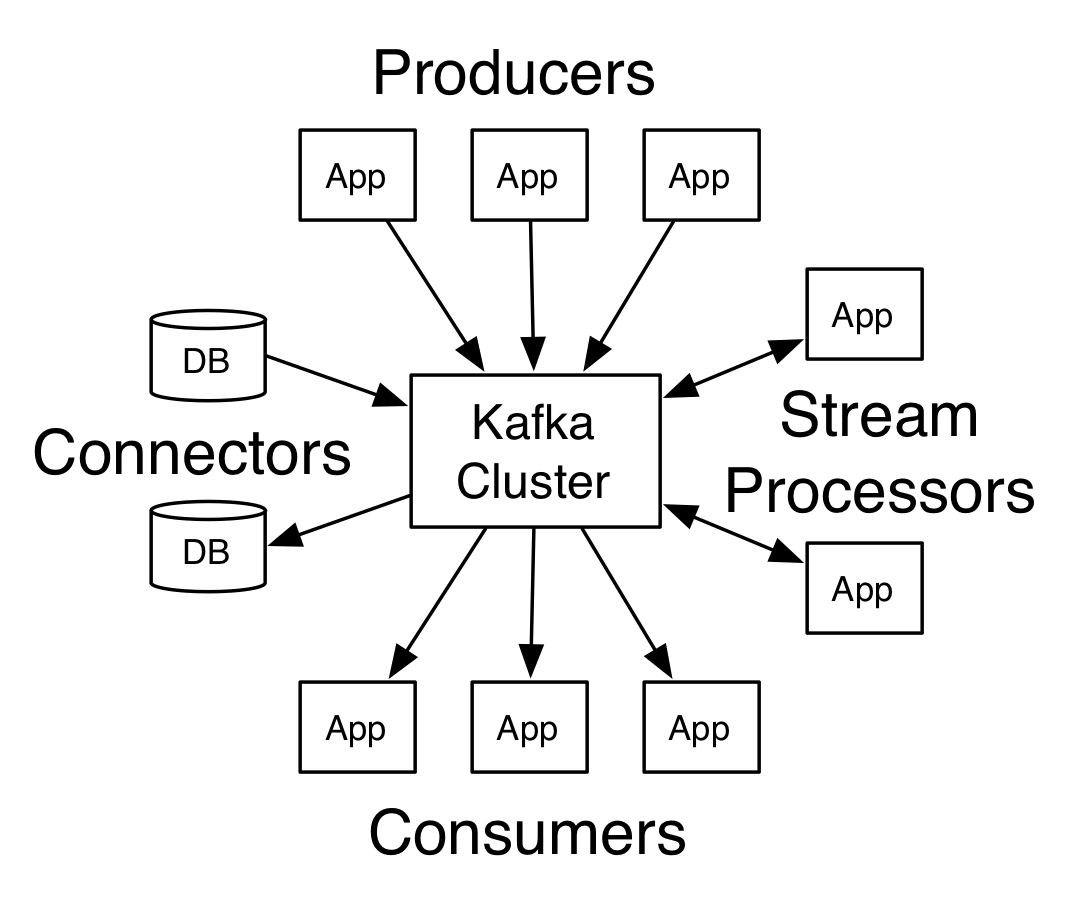
- Kafka is a distributed streaming platform.
- Streaming: real-time messaging pipeline similar to Logstash and different from Elasticsearch that is a static storage.
- Distributed: cluster with fault-tolerance and load balancing.
Kafka receives data from producers while streaming it to consumers (also called subscribers). In this post, words read and consume are used interchangeably; write and produce are used interchangeably. However, read and write emphasize internal actions while produce and consume emphasize interactions with external applications.
-
Kafka and Logstash are both message pipeline.
However, Kafka is more powerful. Basically, Kafka is a cluster while Logstash runs in standalone mode.
They can co-operate: each Logstash instance connects to a Kafka server (also called broker) in the cluster. Logstash instances are not aware of each other.
-
Kafka uses the term record or message while Elastic Stack and Flume use event, namely the data.
Each record comprises timestamp, metadata other key-value pairs.
{"@timestamp":"2019-04-17T09:45:22.361Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.0.0","topic":"var-logs"},"message":"127.0.0.1 - - [17/Apr/2019:09:45:19 +0000] \"GET /index.html HTTP/1.1\" 200 3700 \"-\" \"curl/7.29.0\" \"-\"","log":{"offset":505,"file":{"path":"/var/log/nginx/access.log"}},"input":{"type":"log"},"ecs":{"version":"1.0.0"},"host":{"name":"76595710480d","architecture":"x86_64","os":{"platform":"centos","version":"7 (Core)","family":"redhat","name":"CentOS Linux","kernel":"3.10.0-693.el7.x86_64","codename":"Core"},"containerized":true,"hostname":"76595710480d"},"agent":{"ephemeral_id":"8909f3d3-8037-4288-bf12-7f22e821181b","hostname":"76595710480d","id":"0c54a8df-1b11-421a-b91b-98a18b4d1ff0","version":"7.0.0","type":"filebeat"},"cloud":{"instance":{"id":"i-00000472","name":"apple-dev.novalocal"},"machine":{"type":"8C16G100G"},"availability_zone":"nova","provider":"openstack"}} -
Topic, Partition and Commit Log
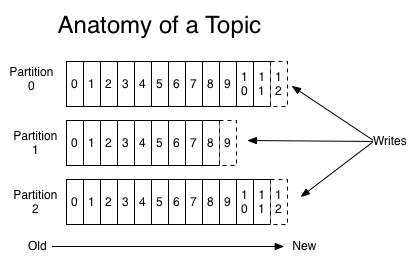
Records are classified into topics: categories of records. We can regard the topic as a label assigned to a group of relevant records (i.e. Nginx logs). Records of a particular topic are stored in one or more (determined at topic creation) partitions with individual records replicated in one or more partitions (determined at topic creation).
A partition is an ordered and immutable sequence of records with new records continuously appended to, similar to an array disallowing random write.
Write in order while read in a free style.
Multiple partitions act as a parallelism to speed up producing and consuming. Additionally, the capacity of a partition may be limited by the Kafka server hold it. So multiple partitions accomplish storage scalability. Typically, partititons reside on dedicated high speed I/O devices like SSD.
Records in partitions form a structured commit log. In the context of Kafka, "log" refers to topic data, NOT the log of Kafka itself. The relevant configuration directive is
log.dir. In this post, we call them commit log and broker log separately. -
Offset
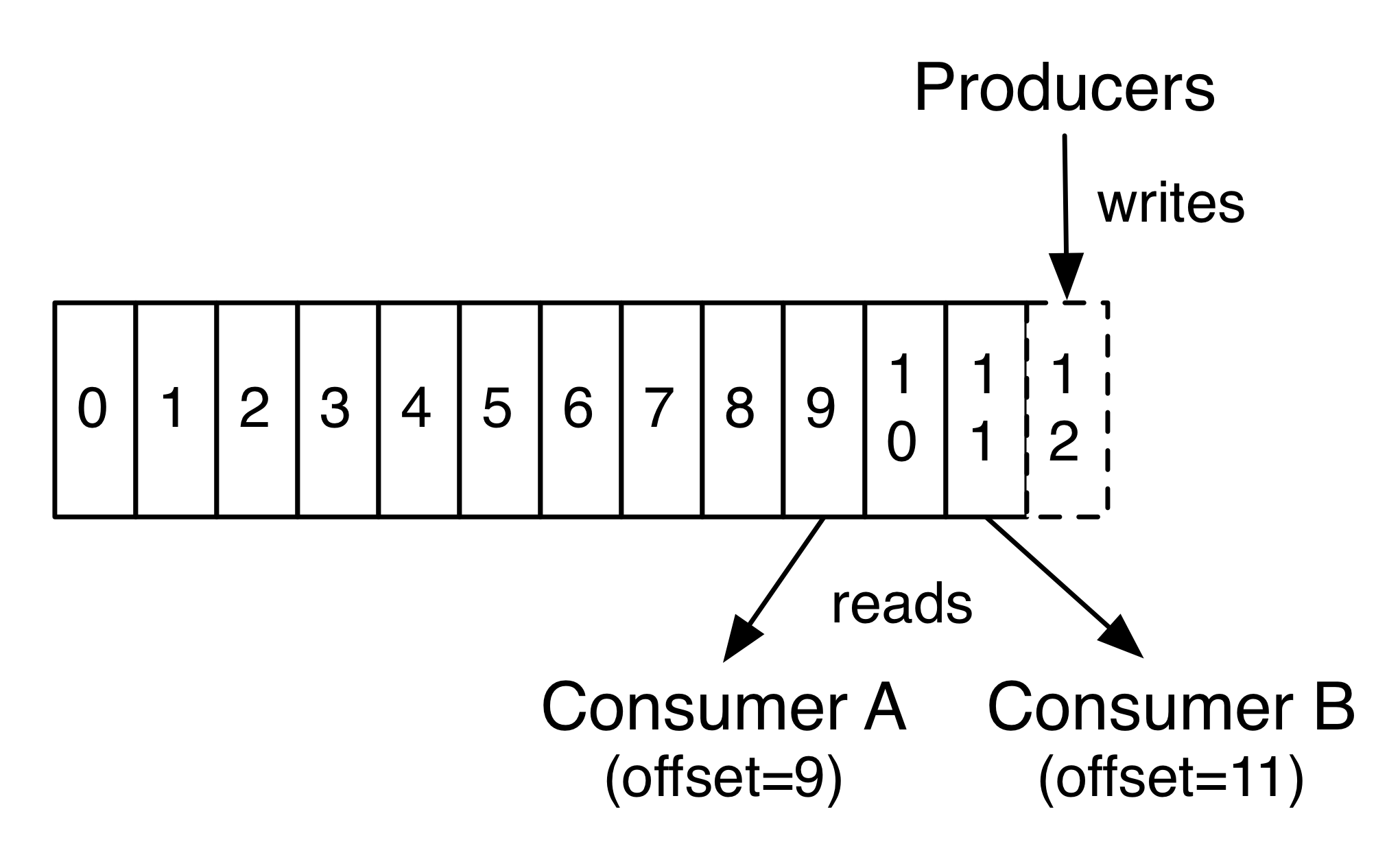
A record is uniquely identified by the index within a partition, which is called offset - the only metadata retained by each consumer. For sequential consumption, the offset is reduced one by one. Consumers are independent of each other. We can use command line tail -F to examine the topic records without interfering in what is and what can be consumed.
Records sent by a particular producer to a particular topic partition are appended in the order they are sent. However Kafka only guarantees such order on a per-partition base. The order of records among consumers, producers and/or partitions are not forseeable. If that is the desired outcome, then configure only one partition for a topic and only one consumer instance per consumer group (discussed below).
-
Persistent Storage
Kafka can be configured to hold records for a retention period of time. During that period, a record is available for consumption, after which it is discarded to free up space.
Consumption does not mean to eat up records but just read. Whether to get rid of a record depends on the retention configuration. The read/write performance is constant with respect to storage size so storing data for a long time is not a problem.
-
Distribution
Each partition is replicated across a configurable number of Kafka brokers - the replication factor for fault tolerance. Of the replicated brokers, one is the leader and the rest are followers (recall the leader and follower of Zookeeper). At any given moment, the leader broker handles both readding and writing operation (different from that of Zookeeper) while the rest brokers only replicate the leader.
A leader has to maintain a list of followers that are in-sync replicas (ISR). An ISR means the follower has fully caught up with the leader, namely synced in time. If a leader fails, one of the ISR followers becomes the new leader.
From the perspective of a Kafka broker, it holds a share of existing partitions and acts as a leader for some of its partitions and a follower for others.
Therefore, load is well balanced within the cluster.
-
Producer
A producer publish data to the records of its choice and decide the partition to which a record is assigned to. The assignment can be done in a round robin fashion to load balance or based on key values.
-
Consumer Group
A topic can have zero or more consumers which are also assigned to labels, forming consumer groups (also called subscriber group). That is to say, all consumers subscribing to a topic are divided into groups. That makes a sense as there may exist multiple entities interested in the same topic, with each entity forms a subscriber group. Consumer instances within a group can be separate threads, processes or machines.
Partitions of a topic are effectively load-balanced over the consumer instances of a subscribing group, in a granularity of partitions. Each instance exclusively consumes zero or more of the partitions at any given time. If there are more instances than partitions, then some of them may be in idle state, consuming nothing. In the other way around, each partition is broadcasted in a granularity of subscribing groups.
In the figure below, there are 4 partitions (P0 - P3) belonging to a particular topic (replication is left out for simplifition). From the figure, each partition is broadcasted to both group A and group B. Within either group, partitions are exclusively distributed.
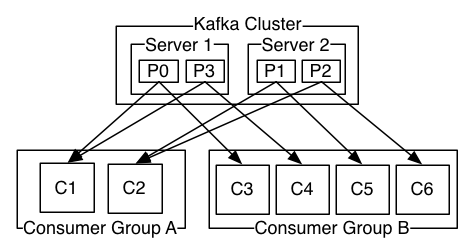
Subscribing groups achieve multi-subscriber support (with the help of persistent storage), namely scalability. Within each group, Kafaka achives parallelism and load balance. The points are:
- Broadcast among groups.
- Exclusive distribution among consumer instances of a group.
A consumer group can be esteemed as a logical subscriber. In terms of scalability, load balance, and fault tolerance:
- Groups can also leave and join the system.
- Instances can dynamically join (get a share from other instances) and/or leave (i.e. die) a group (its partitions are transferred to others).
By the way, consumer group has a unique identifier that is created by Java consumer API, not by ZooKeeper or Kafka producer.
- Early versions of Kafka depends on external Zookeeper. Recent Kafka has built Zookeeper into release packages. More aggressively, Kafka (>= 2.8.0) can run without Zookeeper, with self-managed quorum (e.g. Kafka Raft).
Deployment
This post will deploy a ZooKeeper cluster and Kafka cluster with 3 Docker containers for testing purpose. All the 3 containers reside on the same physical host.
| Container | IP | Servers |
|---|---|---|
| logger1 | 172.17.0.2 | ZooKeeper 1, Kafka 1 |
| logger2 | 172.17.0.3 | ZooKeeper 2, Kafka 2 |
| logger3 | 172.17.0.4 | ZooKeeper 3, Kafka 3 |
References
Prerequisites
- Docker CentOS 7;
- Java 8;
- ZooKeeper MUST be ran before Kafka.
Docker
Account - logger
Create an account 'logger' in both the host and containers. The name 'logger' is chosen to represent ZooKeeper and Kafka respectively. Its home directery is the main place to share critical configuration files. This is optional as we can create the new account within containers directly. It is listed just as a practice.
First create the account in the physical host. We'd better keep the user ID and group ID consistent in case of permission conflicts. In this post, we set both IDs to 555. In Linux practice, manually created user ID and group ID are suggested to be equal to or larger than 1000.
root@tux ~ # groupadd -g 555 logger
root@tux ~ # useradd -ms /bin/bash -u 555 -g logger logger
root@tux ~ # passwd logger
root@tux ~ # id logger
root@tux ~ # su - logger
Create a shared directory between the host and containers:
root@tux ~ # mkdir -p /var/opt/logger
root@tux ~ # chown -R logger:logger /var/opt/logger
Latest CentOS 7
root@tux ~ # docker search centos
root@tux ~ # docker pull centos
root@tux ~ # docker image ls
Dockerfile
- In the Dockerfile, we pass a default password for 'logger', which should be changed after docker attach or docker exec.
- Enable EPEL and IUS, and install a few tools (iproute2 vs net-tools).
FROM centos:latest
RUN groupadd -g 555 logger ; useradd -ms /bin/bash -u 555 -g logger logger ; echo "logger:12345678" | chpasswd
RUN yum install -y epel-release https://centos7.iuscommunity.org/ius-release.rpm
RUN yum install -y sudo iproute most nmap-ncat java-1.8.0-openjdk
CMD ["/bin/bash"]
Remember to change password upon login.
Build Image
The Dockerfile is read from STDIN (dash).
logger@tux ~ $ sudo docker build -t centos-7.6:logger - < Dockerfile
logger@tux ~ $ sudo docker image ls
Create Container
- Create an alias in /etc/hosts for the host IP by
--add-host, making connections to the host easier. - Use the default 'bridge' networking mode; run as the default 'root'.
logger@tux ~ # HOSTIP="$( awk -F $'/|[[:space:]]+' '{print $4}' < <(ip -4 -o address show scope global dev eth0) )"
logger@tux ~ $ sudo docker run --name logger1 -d -it --mount type=bind,source=/var/opt/logger,target=/var/opt/logger -w /var/opt/logger --net bridge --add-host host-eth0:${HOSTIP} --user root:root centos-7.6:logger bash
Container Setup
By default, containers's hostname is set to the value of their IDs. So 'localhost' in sudoers does not work as expected.
root@tux ~ # docker container ls
root@tux ~ # docker attach logger1
root@container ~ # passwd logger
# <new password>
root@container ~ # visudo [-c] -f /etc/sudoers.d/logger
# logger $(hostname) = (root) ALL
root@container ~ # visudo -cf /etc/sudoers.d/logger
root@container ~ # sudo -ll -U logger
Switch to the new account:
root@container ~ # su - logger
logger@container ~ $ echo 'PS1="[\u@\h-logger1 \W]\$ "' >> ~/.bashrc ; source ~/.bashrc
Insert logger1 to PS1, making it easier to differentiate containers on shell prompt.
Java 8
Install JRE:
logger@container-logger1 ~ $ yum repolist
logger@container-logger1 ~ $ java -version
logger@container-logger1 ~ $ yum search java-1.8.0-openjdk
logger@container-logger1 ~ $ sudo yum install java-1.8.0-openjdk.x86_64
logger@container-logger1 ~ $ java -version
System property value can be configured dynamically on command line by java -Dproperty=value. property is a Java variable while value overrides the counterpart set in configuration files. If value is a string with blanks, then quote it.
ZooKeeper Replicated Mode
The installation is quite easy: just download and extract the tarball. Stable versions are recommended! As of writing this post, stable 3.4.14 is available.
Install ZooKeeper to /opt:
logger@container-logger1 ~ $ curl -O /var/opt/logger https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/zookeeper-3.4.14.tar.gz
logger@container-logger1 ~ $ sudo tar -xzpvf /var/opt/logger/zookeeper-3.4.14.tar.gz -C /opt/
logger@container-logger1 ~ $ cd /opt
logger@container-logger1 ~ $ sudo ln -sv zookeeper-3.4.14 zookeeper
logger@container-logger1 ~ $ sudo chown -R logger:logger zookeeper/
logger@container-logger1 ~ $ cd zookeeper/conf/
Next, we focus on the configuration. A sample configuration file is located at zookeeper/conf/zoo_sample.cfg. We are interested in the following directives:
- tickTime: basic unit in milliseconds; heartbeats interval - the tick. The minimum timeout value will be twice the 'tickTime' and the maximum timeout value is 10 times.
- initLimit: timeout for servers in quorum to connect to the leader.
-
syncLimit: timeout between sending a update request to and receiving acknowledgement from a leader.
The two directives are not required in standalone mode.
- dataDir: persistent storage for both snapshots of in-memory data and trasaction logs.
-
dataLogDir: a dedicated directive that defines a different location to store transactions logs.
A separate physical storage device for transaction logs can significantly improve performance of ZooKeeper.
-
clientPort: the port to listen for client (Kafka brokers in this case) connections. By default, it is 2181.
clientPortAddress is the address to listen for client connections. By default, it is '0.0.0.0'.
- autopurge.snapRetainCount: when doing storage cleanup, only retain the most recent version. No less than 3!
- autopurge.purgeInterval: cleanup interval in hour unit.
-
server.X=hostname:port1:port2:
Specify ZooKeeper servers where X is an integer between 1 and 255, being the unique identifier within the ensemble. The first port number port1 (default to 2888) is for followers to connect to the leader; the next port2 (default to 3888) is for leader selection.
Standalone mode does not require the 'server.X' directive, but can also specify a single line like 'server.1=localhost:2888:3888'.
If multiple servers run on a single host, choose separate ports, directroies etc. The name tick is the basic unit in measuring timeout. When setting up ZooKeeper in standalone mode (1 server only), 'initLimit' and 'syncLimit' are ignored as there is no synchronization requirement. Standalone mode is handy when testing development.
The configuration file uses .properties format, and can be any name, but often we use conf/zoo.cfg (check bin/zkEnv.sh). Here is a sample:
tickTime=2000 # 1 tick = 2000 ms = 2s
initLimit=5 # 5 ticks
syncLimit=2 # 2 ticks
dataDir=/var/opt/logger/z1-snapshots # persistent in-memory snapshots
dataLogDir=/var/opt/logger/z1-txnLogs # persistent transaction logs
clientPort=2181
autopurge.snapRetainCount=3 # keep lastest 3 versions
autopurge.purgeInterval=2 # cleanup every 2 hours
4lw.commands.whitelist=* # new in 3.5.3, enable all four-letter commands
server.1=logger1:2888:3888 # communication within Zookeeper cluster
server.2=logger2:2888:3888 # port 2888 used to contact leader
server.3=logger3:2888:3888 # port 3888 used to elect leader
In the example above, the server hostname 'logger1', 'logger2' and 'logger3' is their /etc/hosts aliases, otherwise use IP addresses.
According to the configuration example, create 'dataDir', 'dataLogDir' and create container aliases.
logger@container-logger1 ~ $ mkdir -p /var/opt/logger/z1-{snapshots,txnLogs}
logger@container-logger1 ~ $ sudoedit /etc/hosts
# -or-
logger@container-logger1 ~ $ cat >> /etc/hosts <<EOF
> 12.34.56.71 logger1
> 12.34.56.72 logger2
> 12.34.56.73 logger3
> EOF
logger@container-logger1 ~ $ ping logger1
We are very close to start ZooKeeper now. Before that, file myid under 'dataDir' must be created to define the unique identifier in accord with 'server.X'. Upon startup, a ZooKeeper server gets its identifier by looking up myid. The only content of this file will be interger X:
logger@container-logger1 ~ $ echo '1' > /var/opt/logger/z1-snapshots/myid
For standalone mode, if directive 'server.X' is omitted, 'myid' should be omitted either.
ZooKeeper Startup
ZooKeeper ships with startup scripts bin/zkServer.sh which sources bin/zkEnv.sh to set runtime variables. Have a read at the two scripts before executing. Here is an excerpt from 'zkServer.sh':
nohup "$JAVA" "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
Add 'zookeeper/bin' to 'PATH':
logger@container-logger1 ~ $ sudo chmod -x /opt/zookeeper/bin/*.cmd
logger@container-logger1 ~ $ echo 'PATH=/opt/zookeeper/bin:${PATH}' >> ~/.bashrc ; source ~/.bashrc
logger@container-logger1 ~ $ zkServer.sh
logger@container-logger1 ~ $ zkServer.sh print-cmd
From 'zkEnv.sh', the Java max heap size is set to 1000m by variable 'ZK_SERVER_HEAP' and 'ZK_CLIENT_HEAP', reflected by java -Xmx option. An overwhelming heap size will seriously degrade ZooKeeper performance due to frequent disk swap. The minimal guarantee is that heap size is smaller than memory size.
ZooKeeper Logging
Basically, ZooKeeper uses log4j 1.2 as its logging infrastructure. Its configuration file should either be in the working directory (where 'zkServer.sh' is invoked; not the directory where 'zkServer.sh' resides), or inclued in JAVA 'CLASSPATH'. The default log4j.properties file resides in conf/ directory which is accessible from 'CLASSPATH' as defined in 'zkEnv.sh'.
Variable 'ZOO_LOG4J_PROP' defines the log level and appender (output destination) of Log4j. By default, they are 'INFO' and 'CONSOLE' respectively in 'zkEnv.sh'. About the priorities of different log levels, read the post 'log4j'. Logs appended to 'CONSOLE' actually go to STDERR and STDOUT.
Meanwhile, 'zkServer.sh' redirects STDERR and STDOUT to "${ZOO_LOG_DIR}/zookeeper.out" and runs in background. Variable 'ZOO_LOG_DIR' is set to '.' (the working directory). If it is ran under the home directory '~', zookeeper.out will be created there. Therefore, logs of ZooKeeper are printed to file zookeeper.out in the working directory.
Besides, there are other appenders like 'ROLLINGFILE' and 'TRACEFILE'. Each appender has their own properties defined in 'log4j.properties'. The advantage of 'ROLLINGFILE' is that logs are rotated by property 'MaxFileSize' and property 'MaxBackupIndex'. Multiple appenders can be turned on or off concurrently. For example, both 'CONSOLE' and 'ROLLINGFILE' can be turned on. If 'CONSOLE' is turned off, 'zookeeper.out' is always empty.
Hence, start ZooKeeper with specified 'ZOO_LOG_DIR' and 'ZOO_LOG4J_PROP':
- ZooKeeper logs is located at /var/opt/logger/z1-logs.
- Choose 'ROLLINGFILE' appender.
logger@container-logger1 ~ $ mkdir -p /var/opt/logger/z1-logs
logger@container-logger1 ~ $ ZOO_LOG_DIR="/var/opt/logger/z1-logs" ZOO_LOG4J_PROP="INFO,ROLLINGFILE" zkServer.sh print-cmd
# -or-
logger@container-logger1 ~ $ echo 'export ZOO_LOG_DIR="/var/opt/logger/z1-logs" ZOO_LOG4J_PROP="INFO,ROLLINGFILE"' >> ~/.bashrc ; source ~/.bashrc
logger@container-logger1 ~ $ zkServer.sh print-cmd
Now, the setup of the first ZooKeeper server is completed. We will commit logger1 on which logger2 and logger3 is created.
logger@container-logger1 ~ $ ^P-^Q
logger@tux ~ $ sudo docker stop logger1
logger@tux ~ $ sudo docker commit -a 'logger' -m "copy logger1" logger1 centos-7.6:logger1
logger@tux ~ $ sudo docker image ls
Recall that, each container has a hostname alias associated with a fixed IP in /etc/hosts. So always start the containers in the exact order: logger1, logger2 and logger3, such that the Docker daemon assign IPs in order.
Start and create the containers in order:
logger@tux ~ $ sudo docker start logger1
logger@tux ~ $ sudo docker run --name logger2 -d -it --mount type=bind,source=/var/opt/logger,target=/var/opt/logger -w /var/opt/logger --net bridge --add-host host-eth0:${HOSTIP} --user root:root centos-7.6:logger1 bash
logger@tux ~ $ sudo docker run --name logger3 -d -it --mount type=bind,source=/var/opt/logger,target=/var/opt/logger -w /var/opt/logger --net bridge --add-host host-eth0:${HOSTIP} --user root:root centos-7.6:logger1 bash
Attach to logger2 aned logger3, and adjust the following items:
/etc/sudoers.d/zk
~/.bashrc
conf/zoo.cfg ; mkdir -p /var/opt/logger/z2-{logs,snapshots,txnLogs}
echo '2' > /var/opt/logger/z2-snapshots/myid
zkServer.sh print-cmd
Now, it is time to start the servers. A customized configuration file can be supplied to the command line upon starting (i.e. for debugging) to override the default conf/zoo.cfg:
logger@container-logger1 ~ $ zkServer.sh start [/path/to/zoo.cfg]
logger@container-logger1 ~ $ zkServer.sh status
However, it may report:
Error contacting service. It is probably not running.
This means the ZooKeeper culster are not yet established (i.e. leader election ongoing) though each server is already running. Then try other methods:
logger@container-logger1 ~ $ ps -eF | grep '[z]ookeeper'
logger@container-logger1 ~ $ tail -F ~/var/opt/logger/z1-snapshots/zookeeper.log
zookeeper.log prints many useful information like configuration pathname, hosts aliases resolution, autopurge arguments, tick and timeout, peer election process etc. Specially, there is a line:
Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 datadir /var/opt/logger/z1-txnLogs/version-2 snapdir /var/opt/logger/z1-snapshots/version-2
datadir refers to the location where transaction logs are stored; snapdir refers to that of in-memory snapshots. Please pay attention that these two name is different than those in zoo.cfg. datadir corresponds to directive 'dataLogDir' while 'snapdir' corresponds to directive 'dataDir'. Read PurgeTxnLog API.
ZooKeeper Status
logger@container-logger1 ~ $ zkServer.sh
logger@container-logger1 ~ $ pgrep -u logger -P 1 -ac -f 'java.*\/home\/logger\/zookeeper\/bin'
logger@container-logger1 ~ $ zkServer.sh status
# zkServer.sh status
# ZooKeeper JMX enabled by default
# Using config: /opt/zookeeper/bin/../conf/zoo.cfg
# Mode: follower
The 'Mode' line tells if a server is a leader or a follower.
Apart from the script wrapper 'zkServer.sh', ZooKeeper can respond to a predefined set of four-letter commands. We issue the commands to servers' (TCP/UDP) sockets via telnet or nc, at the client port (default 2181):
logger@container-logger1 ~ $ rpm -q nmap-ncat.x86_64
logger@container-logger1 ~ $ nc localhost 2181 <<< 'dump'
logger@container-logger1 ~ $ echo 'srvr | stat | envi' | nc localhost 2181
From ZooKeeker 3.5.3 onwards, by default only 'srvr' is enabled. We should configure property '4lw.commands.whitelist' to turn on desired commands.
Another wrapper script 'zkCli.sh' connects to servers and perform filesystem-like operations:
logger@container-logger1 ~ $ zkCli.sh -server localhost:2181 help # print help message
logger@container-logger1 ~ $ zkCli.sh -server localhost:2181 # interactive ZooKeeper shell
# [zk: localhost:2181(CONNECTED) 0] help # print help message
# [zk: localhost:2181(CONNECTED) 0] ls / # list the 'root' znode
# [zk: localhost:2181(CONNECTED) 0] create /zk_test my_data # creat a new znode directory
# [zk: localhost:2181(CONNECTED) 0] ls /
# [zk: localhost:2181(CONNECTED) 0] set /zk_test my_new_data
# [zk: localhost:2181(CONNECTED) 0] get /zk_test
# [zk: localhost:2181(CONNECTED) 0] delete /zk_test
# [zk: localhost:2181(CONNECTED) 0] ls /
# [zk: localhost:2181(CONNECTED) 0] quit
ZooKeeper Storage
- For a long running production system, persistent storage must be managed manually or automatically by autopurge mentioned above.
- Recall that logs of ZooKeeper itself is rotated automatically by 'ROLLINGFILE'.
To manually purge history snapshots and related transaction logs:
logger@container-logger1 ~ $ cd /opt/zookeeper/
logger@container-logger1 ~ $ java -cp zookeeper-3.4.14.jar:lib/slf4j-api-1.7.25.jar:lib/slf4j-log4j12-1.7.25.jar:lib/log4j-1.2.17.jar:conf org.apache.zookeeper.server.PurgeTxnLog <datadir> <snapdir> -n <count>
- datadir ('dataLogDir') and snapdir ('dataDir') can be found either from zookeeper.log, in zoo.cfg, or by the four-letter command
conf. -n <count>means to keep the last 'count' snapshots and transaction logs, which should be no less than 3 conventionally.- Make sure the correct classpath is provided.
- Create a cron job.
Actually, ZooKeeper provides a built-in 'zkCleanup.sh' script to wrap the Java command:
logger@container-logger1 ~ $ zkCleanup.sh --help
'zkCleanup.sh' accepts the same arguments as above and makes cron jobs much eaiser. However, ZooKeeper 3.4.0 onwards already supports autopurge, why not just use the built-in feature?
Stop ZooKeeper
logger@container-logger1 ~ $ zkServer.sh stop
ZooKeeper Systemd Unit
Read the post Zookeeper install on CentOS 7 first.
Zookeeper Advanced Tips
Dynamic Reconfiguration
From 3.5.0 onwards, directives 'clientPort' and 'clientPortAddress' can be integrated into the 'Server.X' directive as:
# server.X = <address1>:port1:port2[:role];[<client port address>:]<client port>
server.1 = 12.34.56.78:2888:3888;2181
server.2 = 12.34.56.78:2888:3888:participant;2181
server.3 = 192.168.0.105:2888:3888:observer;12.34.56.78:2181
Dynamic Reconfiguration means to update confiuration on the fly without restarting ZooKeeper servers.
Observer Server
As mentioned earlier, at least a quorum of the active servers are synched on a 'write' operation. However, this requirement make it hard to scale the number of ZooKeeper servers and/or the number of clients as write sync takes time and resources.
ZooKeeper now introduces a new type of server called observer to improve scalability, distinguished from the common participant servers. Observers are almost the same as participant followers except that they does not participate in write sync and only receive the sync results.
Therefore, we can increase the number of observers as much as we like without harming the write sync performance. To specify an observer server, the configuration looks like:
peerType=observer
server.1=localhost:2888:3888:observer;2181
Kafka
Kafka Installation
Like that of ZooKeeper, the installation process of Kafka is quite straightforward, download and untar.
A kafka distribution is named as 'kafka_scalaVersion-kafkaVersion.tgz`. Each Kafka version may have multiple scala disbributions, and vice versa. As of the post, the Scala version is 2.12 while Kafka version is 2.2.0.
logger@container-logger1 ~ $ curl -O /var/opt/logger/ https://www-eu.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
logger@container-logger1 ~ $ sudo tar -xzpvf /var/opt/logger/kafka_2.12-2.2.0.tgz -C /opt/
logger@container-logger1 ~ $ cd /opt
logger@container-logger1 ~ $ sudo ln -sv kafka_2.12-2.2.0 kafka
logger@container-logger1 ~ $ sudo chown -R logger:logger kafka/
logger@container-logger1 ~ $ ll kafka/config
Kafka Configuration
Now configure server.properties:
# similar to ZooKeeper 'myid'; a unique integer
broker.id=1
# comma-separated listeners
listeners=PLAINTEXT://0.0.0.0:9092,EDGE://1.2.3.4:9093,USA://5.6.7.8:9094
# advertised listners
advertised.listeners=PLAINTEXT://0.0.0.0:9092,EDGE://1.2.3.4:9093,USA://5.6.7.8:9094
# listner for inter-broker communication
inter.broker.listener.name=PLAINTEXT
# listener name mapping to security prototol
listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL,EDGE:PLAINTEXT,USA:PLAINTEXT
# commit logs location; high speed SSDs
#log.dir=/tmp/kafka-logs
# default to 'log.dir'
log.dirs=/home/zk/kafka/commitLogs
# default partitions per topic
num.partitions=3
# replication factor for internal topics like "__consumer_offsets"
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=2
# ZooKeeper servers
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zookeeper.connection.timeout.ms=3000
-
listeners
Listeners are what interfaces a Kafka broker bind to.
The directive is a list of comma-separated listeners. Each listener is actually a TCP socket on the broker and is associated with a name, hostname/IP, and port.
# listeners = listener_name://my.host.name:portSpecify hostname as '0.0.0.0' to bind to all interfaces. Leave hostname empty to bind to the default interface. A hostname can be resolved to multiple IPs to do load balance. If this directive is not set, it defaults to 'PLAINTEXT://0.0.0.0:9092'.
A listener should be mapped to a security protocol by its name for connection authentication, and thus often named after a security protocol:
$ name to security protocol map listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSLSo we cannot define two listeners with the same name.
# error: two listners with the same name listeners=PLAINTEXT://192.168.1.100:9092,PLAINTEXT://12.34.56.78:9092Multiple listeners MUST have different ports.
-
advertised.listeners
Advertised listeners are what interfaces a client (producer/consumer) connects to.
A listener is firtly published to the ZooKeeper cluster, then spreaded to all other Kafka brokers, and finally to clients. The limitation is that a listener can be advertised only once.
- Communication within the cluster brokers and can be achieved through any defined listeners. Clients get the cluster metadata from any defined listeners as well.
- However, read and/or write connections are only done through advertised listeners. Hence, usually we advertise listeners with public IP.
listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://12.34.56.78:9092The design of multiple listeners defined and/or advertised gives a fair amount of flexibility. For example, we can advertise a listener for internal clients while another one for external clients. Additionally, a separate advertised listener for replicated partition traffic is desired. Directive 'inter.broker.listener.name' can be set to a listener for traffic between brokers like:
inter.broker.listener.name=PLAINTEXTIf not properly advertised, a client may fail to produce or consumer data. For example, if a listener is bound to '0.0.0.0:9092' but only advertise the LAN address '192.168.1.100:9092', clients could still initiate a connection to the broker through '12.34.56.78:9092' (public IP), fetching metadata about brokers. When it comes to read and/or write data, clients can only contact the advertised addresses enclosed in metadata. That demonstrates the difference between reachable socket and reachable service.
We CANNOT advertise a listener with '0.0.0.0'.
- 'log.dirs' is a list comma-separated locations to store commit logs. If not set, it defaults to 'log.dir' that is a single location. 'log.dir' defaults to /tmp/kafka-logs.
- ZooKeeper listens for Kafka connections at port 2181; Kafka listens at port 9092.
Start Kafka
Before starting brokers, create directories and change 'PATH':
logger@container-logger1 ~ $ mkdir -p /var/opt/logger/k1-logs
logger@container-logger1 ~ $ echo 'PATH=/opt/kafka/bin:${PATH}' >> ~/.bashrc ; source ~/.bashrc
Kafka has a bunch of built-in scripts, of which 'kafka-server-start.sh' and 'kafka-run-class.sh' are responsible for starting the service. In the scripts, there is a special variable 'base_dir' setting the base directory (recall 'ZOO_LOG_DIR' of ZooKeeper) that defaults to Kafka installation directory.
Similar to ZooKeeper, Kafka also utilize 'Log4j' to trace broker logs affected by environment variables 'LOG_DIR', and 'KAFKA_LOG4J_OPTS', and Java property 'kafka.logs.dir'
# Script 'kafka-server-start.sh':
# Log4j property file
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"
# Script 'kafka-run-class.sh'
LOG_DIR="$base_dir/logs"
From the definition, broker logs default to kafka/logs where Kafka is installed, including 'server.log', 'state-change.log' and 'controller.log' (recording leader election).
We can just leave brokers logging to the defauts. OK, start the server:
logger@container-logger1 ~ $ kafka-server-start.sh
# USAGE: /opt/kafka/bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
# explictly provide 'server.properties'
logger@container-logger1 ~ $ kafka-server-start.sh -daemon /opt/kafka/config/server.properties
-daemonoption put Kafka into background.- Unlike ZooKeeper, Kafka requires explicit pathname of property file.
-
--overridechanges default properties. For example, to change the location of broker logs, either modify property 'kafka.logs.dir' or environment variable 'LOG_DIR'logger@container-logger1 ~ $ mkdir -p /var/opt/br1-logs logger@container-logger1 ~ $ LOG_DIR=/var/opt/br1-logs kafka-server-start.sh ... # -or- logger@container-logger1 ~ $ kafka-server-start.sh ... --override kafka.logs.dir=/var/opt/br1-logs
Repeat the above setup for the other two Kafka servers.
Kafka Status
We can verify if the server was started correctly through ZooKeeper dump:
logger@container-logger1 ~ $ ps -eF | grep '[k]akfka'
logger@container-logger1 ~ $ ss -npelt
logger@container-logger1 ~ $ pgrep -u logger -P 1 -ac -f 'java.*\/home\/logger\/kafka\/bin'
logger@container-logger1 ~ $ tail -F /var/opt/br1-logs/server.log
logger@container-logger1 ~ $ nc localhost 2181 <<< "dump"
Here is a sample output:
SessionTracker dump:
Session Sets (4):
0 expire at Sat Feb 21 00:11:04 UTC 1970:
0 expire at Sat Feb 21 00:11:06 UTC 1970:
0 expire at Sat Feb 21 00:11:08 UTC 1970:
3 expire at Sat Feb 21 00:11:10 UTC 1970:
0x2010197720b0000
0x301019c5afd0000
0x301019c5afd0001
ephemeral nodes dump:
Sessions with Ephemerals (3):
0x301019c5afd0000:
/brokers/ids/2
0x301019c5afd0001:
/brokers/ids/3
0x2010197720b0000:
/controller
/brokers/ids/1
From the excerpt, we know ZooKeeper create an individual znode for each Kafka server, within the namespace tree. To further investigate:
logger@container-logger1 ~ $ zkCli.sh -server localhost:2181 ls /
# [cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
logger@container-logger1 ~ $ zkCli.sh -server localhost:2181 get /brokers/ids/1
# [1, 2, 3]
Stop Kafka
When a broker is gracefully stopped, it may take advantage of:
-
Commit logs are synced to disk to avoid logs recovery upon restart.
Log recovery taks time as checksum validation is required for all entries in the tail of the log.
-
Partitions this broker is the leader for are synchronized to followers, which significantly increase the process of new leader election - leadership migration.
This requires that the topic replication factor is greater than 1 (i.e.
--replication-factor=2), otherwise this single leader would sync the partitions nowhere and commit logs would be unavailable! A replication factor greater than 1 is always what we want!Another requirement, is directive controlled.shutdown.enable is set to true (default).
To gracefully stop a broker:
logger@container-logger1 ~ $ kafka-server-stop.sh
The script does not accept any options and just sends 'SIGTERM' signal to the Kafka process. So don't try to pass --help as it inevitably stops the service.
- Stop Kafka before ZooKeeper;
- It takes time to stop Kafka cluster, so wait for while!
Topic Creation
Kafka provides a simple console producer and consumer script, quite handy for test.
Before Kafka version 0.9, built-in scripts require the option --zookeeper to specify one or more ZooKeeper servers to connect to as offset data is stored within ZooKeeper. The offset data is now moved into Kafka itself (the built-in __consumer_offset topic). So --zookeeper option is depcreated in favor of option --bootstrap-server using brokers.
Firstly, create a test topic:
logger@container-logger1 ~ $ kafka-topics.sh
logger@container-logger1 ~ $ kafka-topics.sh --zookeeper logger1:2181,logger2:2181 --list
logger@container-logger1 ~ $ kafka-topics.sh --bootstrap-server logger1:9092,logger2:9092,logger3:9092 --create --replication-factor 2 --partitions 3 --topic test-topic
logger@container-logger1 ~ $ kafka-topics.sh --bootstrap-server logger2:9092 --list
logger@container-logger1 ~ $ kafka-topics.sh --bootstrap-server logger2:9092 --describe --topic test-topic
# Topic:test-topic PartitionCount:3 ReplicationFactor:2 Configs:segment.bytes=1073741824
# Topic: test-topic Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3
# Topic: test-topic Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3,1
# Topic: test-topic Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
-
--replication-factordefines the number of replicas.It is a must!
--partitionsoverrides 'num.partitions' in 'server.properties'.- The topic has 3 partitions.
- From the output of
--describe, replicas in all followers are in-sync replicas.
Console Producer and Consumer
Next, we launch a consumer on the topic:
logger@container-logger1 ~ $ kafka-console-consumer.sh
logger@container-logger1 ~ $ kafka-console-consumer.sh --bootstrap-server logger2:9092 --topic test-topic --from-beginning
No explicit consumer group is created here. By default, 'kafka-console-consumer.sh' will create a random group ID through Java consumer API.
Then start a producer with --broker-list:
logger@container-logger2 ~ $ kafka-console-producer.sh --help
logger@container-logger2 ~ $ kafka-console-producer.sh --broker-list logger1:9092,logger2:9092,logger3:9092 --topic test-topic
# hello, world
Now everything typed in the producer console will be automatically printed in the consumer console. Check partitions:
logger@container-logger1 ~ $ zkCli.sh -server localhost:2181 get /brokers/topics/test-topic/partitions/1
Use ^C to stop the consumer and producer.
Consumer Group
Let's play around consumer group.
Firstly, we want a list of existing consumer groups either by ZooKeeper interface or by Kafka interfaces.
logger@container-logger1 ~ $ zkCli.sh -server localhost:2181 ls /consumers
# < 0.9: consumers contact ZooKeeper
logger@container-logger1 ~ $ kafka-consumer-groups.sh --zookeeper logger1:2181 --list
# >= 0.9: consumers contact Kafka directly by Java consumer API
logger@container-logger1 ~ $ kafka-consumer-groups.sh --bootstrap-server logger1:9092 --list
logger@container-logger1 ~ $ kafka-consumer-groups.sh --bootstrap-server logger1:9092 --describe --group consumer-group-name
Next, we try to create an explicit consumer group. A consumer can join an existing group (implicit default included) or create a new one:
-
--group consumer-group-name1This is the most obvious option.
-
--consumer.config filename;# /path/to/filename group.id=consumer-group-name2 -
--consumer-property group.id=consumer-group-name3These two options are done through direct Java property.
-
If the provided name exsit, then the new consumer join the group, otherwise the group would be created.
logger@container-logger1 ~ $ kafka-console-consumer.sh --bootstrap-server logger1:9092 --topic test-topic --group consumer-group-12345
logger@container-logger1 ~ $ kafka-console-consumer.sh --bootstrap-server logger1:9092 --topic test-topic --consumer.config consumer-group-12346
logger@container-logger1 ~ $ kafka-console-consumer.sh --bootstrap-server logger1:9092 --topic test-topic --consumer-property group.id=consumer-group-12347
logger@container-logger2 ~ $ kafka-consumer-groups.sh --bootstrap-server logger2:9092 --describe --group consumer-group-12345
Kafka Security
Post introduction-to-apache-kafka-security gives a clear outline on Kafka security mechanisms. It recommends SASL/SCRAM method (Zookeeper only supports SASL/DIGEST-MD5).
Kafka uses Java Authentication and Authorization Service (JAAS) for both server side security setup and client side authentication.
There are two ways to provide JAAS data (e.g., SASL).
-
Configuration property string in .properties like
sasl.jaas.config=. This is the recommended method.Below is an example. Please make sure the trailing semi-colon is present.
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="(username)" password="(password)";Built-in CLI clients can automatically detect the security setup. If not, add option
--command-stringto kafka-topics.sh, or option--producer.configto kafka-console-producer.sh. -
JAAS file. For example, on server side, we can pass the static file as below.
export KAFKA_OPTS="-Djava.security.auth.login.config=/path/to/kafka_jaas.conf"
Dynamic Update Mode
From Kafka 1.1 onwards, directives could be updated/overriden dynamically. The Broker's Dynamic Update Mode column may be:
- read-only: requires restart for update;
- per-broker: can be updated for each broker on the fly;
- cluster-wide: can be updated for all brokers; may also be updated for an individual broker.
- Some directives can be changed dynamically per-topic, like the directive 'num.partitions'.
To get a list of supported directives on command line:
logger@container-logger1 ~ $ kafka-configs.sh --help
To check current broker configuration:
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-name 2 --describe
Change number of cleanup threads for commit logs:
# per-broker
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-name 2 --alter --add-config log.cleaner.threads=2
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-name 2 --describe
To apply the change to all brokers, use option --entity-default:
# cluster-wide
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-default --alter --add-config log.cleaner.threads=2
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-default --describe
To revert the dynamic modification and restore the static value configured:
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-name 2 --alter --delete-config log.cleaner.threads
logger@container-logger1 ~ $ kafka-configs.sh --bootstrap-server logger1:9092 --entity-type brokers --entity-name 2 --describe
A directive may be configured at multiple levels in the follow order of precedence:
- Dynamic per-broker;
- Dynamic cluster-wide;
- Static in 'server.properties';
- Kafka default.