Elastic Stack
10 Apr 2019 • Leave CommentsTop-down Architecture
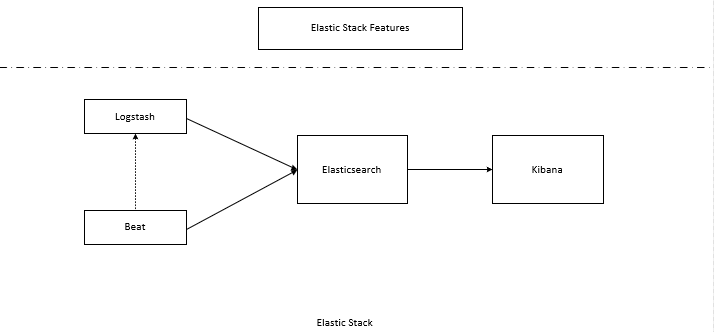
Elastic Stack is called ELK previously. Due new products like Beats and X-Pack, the acronym is changed accordingly.
-
Kibana
The frontend of the stack: search and virtualize data like charts and tables.
-
Elasticsearch
Jason-based search engine (based on Lucene): index, analyze and store data as Json format.
From the figure above, we know that Elasticsearch is the heart of the stack. We will find below that the Elastic Stack repository (for CentOS) is called elasticsearch.
-
Logstash
stash [vt] to store in a usually secret place for future use
Data collection pipeline: unify and normalize data. The name comprises 'log' and 'stash'. 'log' means the input (source data) while 'stash' means output (store the data). Between the input and output, there is the optional filter component. Logstash has now evolved into a more general tool. It can even receive data from and/or send data to Kafka (another FOSS project).
Logstash will format the data in Json format and send out to Elasticsearch (the stash).
-
Beats
beat [c] A stroke or blow. In music, a beat is a unit of measurement.
Agent: ships different types of data from edge devices to Logstash or directly to Elasticsearch.
There are different kinds of beats desginated for different kinds of data. For example, Filebeat is to collect log files (i.e. access.log and error.log) with modules. A Nginx module collects Nginx log files; a MySQL module collects MySQL log files. Another beat is Metricbeat that collects system-level and/or service-level performance metrics like CPU and memory usage for the operating system. It also ships with modules for popular services such as Nginx, MySQL etc.
-
Elastic Stack Features
Formerly known as X-Pack - addons: a pack of extensions to the stack, like authentication, monitoring & altering, reporting, Elasticsearch SQL, and machine learning (abnormality detection, forecasting, relation graph).
For relation graph, pay attention to the difference between relevance and popularity. Mostly, relevance is what we desire. All colleagues use Google search in a team does not mean they are relevant as per Google: it is just becuase Google is popular.
Installation
Reference
Prerequisites
- Java 8
- Use the same version across the entire stack.
- Follow the order: Elasticsearch, Kibana, Logstash, Beats etc.
- Each component can be installed by justing extracting tarballs or through official 'yum' repository.
Repo
Import key:
user@tux ~ $ sudo rpmkeys --import https://packages.elastic.co/GPG-KEY-elasticsearch
Add the repository:
user@tux ~ $ cat >> /etc/pki/rpm-gpg/elastic-stack.repo <<EOF
> [elastic-7.x]
> name=Elastic repository for 7.x packages
> baseurl=https://artifacts.elastic.co/packages/7.x/yum
> gpgcheck=1
> gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
> enabled=1
> autorefresh=1
> type=rpm-md
Search for a package:
user@tux ~ $ yum search elasticsearch kibana
Logstash
Congfiguration file format is writen in a format similar to Json.
Filebeat
- Filebeat support various outputs but we usually just send the events directly to Elasticsearch or to Logstash for additional processing. Events can also be sent to products out of the Elastic Stack like Kafka.
- Filebeat uses backpressure-sensative protocol to do congestion control, adjusting the speed of reading log entries in accord with Logstash or Elasticsearch staus.
-
'inputs' generate 'event's in Json format; 'processors' filters events; 'output' ships events out.
'field' refers to the key part of an event 'key: value' pair.
Install Filebeat
user@tux ~ $ yum search filebeat
user@tux ~ $ yum install filebeat
user@tux ~ $ rpm -ql filebeat
The package includes a sysvinit script, namely /etc/init.d/filebeat. In the 'Filebeat Start' section, we will discuss how to utlize this script for Sytemd startup.
Beats YAML
This applies to all beats applications.
Configuration is writen in YAML format, demanding strict indentation. All settings are structured using dictionaries and lists. Please use the same number of spaces and avoid tabs for dictionary pairs and list items. The structured form collapses to a namespaced naming method.
Dictionary is represented with key: value pairs in the same indentation level, with the ':' separator followed by a space or newline. Multiple pairs can be put on the same line in an abbreviated form:
# Enclosed by braces
person: {name: "John Doe", age: 34, country: "Canada"}
A list item takes the form: - , namely a dash followed by a space. All list items of a list should be at the same indetation level. In the following example, 'colors' is a dictionary 'key' with the value part a list consisted of three items.
colors:
- Red
- Green
- Blue
Multiple list items can also be abbreviated as:
# Enclosed by square brackets
colors: ["Red", "Green", "Blue"]
Whenever a semicolon appears followed by a space, it is a dictionary pair. Whenever a dash followed by a space, it is a list item.
Configuration Notice:
- Please use single quotes for regex and pathnames that containing spaces or special characters.
-
System environment variables and configuration variables (defined within YML itself) are referenced in the form
${VAR:default-value}. Environment variables are expanded before YAML parsing. So we CANNOT refer to system environment variables within YAML files of 'Live Reloading' as those files are reloaded periodically but after the main YAML parsing.The command line
-Eoption can be used to override variables like-E key=value. - Aside environment and configuration variable reference, event field can be referenced in the form
%{[field-name]:default-value}. Pay attention please, the prefix symbol is%. Event fields are accessed using field references[field-name]. This is called Format String (sprintf).
Filebeat Configuration
By default, configuration files are installed to /etc/filebeat:
user@tux ~ $ ll /etc/filebeat/
> total 300
> -rw-r--r-- 1 root root 219620 Apr 5 22:11 fields.yml
> -rw-r--r-- 1 root root 71973 Apr 5 22:11 filebeat.reference.yml
> -rw------- 1 root root 7745 Apr 5 22:11 filebeat.yml
> drwxr-xr-x 2 root root 4096 Apr 18 08:06 modules.d
All configuration files are writen in YAML format. For pre-defined fields, check the installed 'fields.yml'. 'filebeat.reference.yml' is the reference sample. 'filebeat.yml' is the default configuration. 'modules.d' contains built-in configurations for modules like Nginx, Apache etc. Filebeat supports Golang glob syntax. Especially, globstar can be enabled by directive 'recursive_glob.enabled' (default to 'true').
The following are hands-on configuration practice:
-
Paths
# default to the location of the Filebeat binary path.home: "/opt/filebeat" # configuration location path.config: ${path.home} # data location path.data: ${path.home}/data # Agent logs path.logs: ${path.home}/logs # By yum repo path.home: /usr/share/filebeat path.config: /etc/filebeat path.data: /var/lib/filebeat path.logs: /var/log/filebeat'path.home' is usually set to the installation location.
-
# Filebeat's global options filebeat.registry.path: ${path.data}/registry # General options that are supported by all Elastic beats name: "filebeat-log-project" tags: ["project-X", "nginx"] fields_under_root: false fields: {project: "X", instance-id: "574734885120952459"}The registry file stores the state and location information that Filebeat uses to track where it was last reading. If a relative path is passed, it is considered relative to the data path. It defaults to
${path.data}/registry.The general 'fields_under_root' field applies to field 'fields' that is added to the event.
-
Logging
logging.level: info #logging.selectors: ["*"] logging.to_files: true logging.to_syslog: false logging.json: false logging.files: path: ${path.home}/logs name: filebeat.log rotateeverybytes: 10485760 keepfiles: 7 permissions: 0644- Log settings for the Filebeat agent itself. If the 'path' is a relative pathname, it would be relative to the 'path.home'.
- Log options can be modified on command line directly. For example,
-d '*'enables debug level for all components.
-
HTTP Server
http.enabled: true http.host: localhost http.port: 5066Filebeat has a built-in HTTP server, exposing internal metrics.
~$ curl http://localhost:5066/?pretty ~$ curl http://localhost:5066/stats?pretty -
Like many other services, Filebeat can load configurations from external files. In 'filebeat.yml', we can set values of key 'filebeat.inputs' and key 'filebeat.modules' from extra YAML files.
For inputs:
filebeat.config.inputs: enabled: true path: inputs.d/*.yml reload.enabled: true reload.period: 10sEach file matched by the 'path' glob must contain a list of one or more inputs.
For modules:
filebeat.config.modules: enabled: true path: ${path.config}/modules.d/*.yml reload.enabled: true reload.period: 10sIf the subcommand
filebeat modulesis used to disable or enable modules, then 'path' MUST point to a location called modules.d. Similarly, each matched globbing must contain a list of one or more module definitions (i.e.- module: nginx).However, live reloading is limited sometimes. For example, if a system environment variable is modified or defined, the process wound not know about it unless restarted.
-
Modules and Inputs
Filebeat reads logs from either 'filebeat.inputs' or 'filebeat.modules'. 'filebeat.inputs' is mainly used to read arbitrary log files while modules read common service logs with predefined settings that is quite handy.
filebeat.modules: - module: nginx access: enabled: true var.paths: /var/log/nginx/access.log error: enabled: true var.paths: /var/log/nginx/error.log filebeat.inputs: - type: log enabled: true paths: - /var/log/myJson.log scan_frequency: 10s exclude_files: ['.gz$','~$'] fields_under_root: true fields: hostname: "${HOSTNAME:-}" json.keys_under_root: true json.overwrite_keys: false json.message_key: "hostHeader" include_lines: ['www.bing.com','www.example.com'] exclude_lines: ['a-shit-hostHeader','b-shit-HostHeader']- 'paths' must be unique among multiple inputs. If more than one inputs harvests the same file, it would lead to unexpected behavior.
- Only log entries whose 'hostHeader' value matching 'include_lines' will be harvested.
- 'include_lines' is applied before 'exclude_lines' regardless of the order they appear.
- Read more about modules configuration.
-
Processors
Processor is probably one of the most important general option. A processor filters input logs by adding/dropping/modifying fields and/or events. It resembles 'exlude_files', 'include_lines' and 'exclude_lines' which are applied upon inputs. Processors, on the other hand, applies to fields/events after inputs and before put to outputs.
An event can go through a chain of processors in the exact order they are defined, before sending out.
processors: - include_fields: fields: ["cpu"] - drop_fields: fields: ['@timestamp', '@metadata', "log", "tags", "input", "ecs", "host", "agent", "message"] - drop_event: when: equals: http.code: 200 - decode_json_fields: fields: ["message"] process_array: false max_depth: 1 target: "" overwrite_keys: trueMore about processors, please check the 'Filebeat Processors' section below.
-
Outputs
Here is an excerpt of outputing to Kafka:
output.kafka: enabled: true hosts: ["logger1:9092", "logger2:9092", "logger3:9092"] # initial broker seeds to retrieve metadata of Kafka and Zookeeper topic: "cdn-sre" #topics: partition.round_robin: reachable_only: true group_events: 3 version: '2.0.0' codec.json: pretty: false escape_html: false worker: 3 compression: gzip required_acks: 1 max_message_bytes: 1000000 client_id: ${HOSTNAME:localhost}- The 'hosts' provides only the initial list of Kafka
listenersfrom which to fetch the whole cluster metadata, including the full list ofadvertised.listenerswhere events are published to. - Besides the 'topic' directive, there is also a 'topics' sub-directive that filters events and publish them to different Kafka topics. It is a useful feature is not constrained by the one and only one
outputrule. That is to say, 'output.kafka' can publish events to multiple topics. - 'group_events' and 'worker' can be set the same value.
- 'max_message_bytes' should be equal to or less than the Kafka broker's 'message.max.bytes'
Like the console consumer/producer of Kafka, Filebeat can output events into console and/or files.
output.file: enabled: true codec.json: pretty: true escape_html: false path: ${path.logs} filename: filebeat.out rotate_every_kb: 10000 number_of_files: 7 output.console: enabled: true codec.json: pretty: true escape_html: falseBeats support one and only one output. If you desire multiple outputs, then send to Logstash or Kafka first.
- The 'hosts' provides only the initial list of Kafka
Filebeat Pre-start
This applies to all beats applications.
On POSIX systems, configuration files are subject to ownership and permission checks:
- The owner of configuration files must be the user that is running the beat applications or the root account.
- The permissions of configuration files permit 'write' only by the owner itself which can be 0644 or 0600.
- The permission and owner checks can be disabled temperarily on command line by
--strict.perms=false.
Filebeat supports a set of commands like help, test, export, modules etc. We can use test to check configuration syntax:
user@tux ~ $ beatname help test
user@tux ~ $ beatname test config -c /path/to/beatname1.yml
# verify if Filebeat can connect the outputs:
user@tux ~ $ beatname test output -c /path/to/beatname1.yml
By default, all built-in modules are disabled, the module command can manage modules on the fly, similar to the mechanism of 'filebeat.config.inputs':
user@tux ~ $ filebeat modules list
user@tux ~ $ filebeat modules enable nginx
user@tux ~ $ filebeat modules disable nginx
Command export exports current config to STDOUT without comments:
user@tux ~ $ filebeat export config
Start Filebeat
Firstly enable Filebeat on boot:
user@tux ~ $ sudo chkconfig --add filebeat
user@tux ~ $ sudo chkconfig --list filebeat
chkconfig creates corresponding symlinks under /etc/rc.x/ according to the Chkconfig Header. /usr/lib/systemd/system-generators/systemd-sysv-generator of Systemd will then auto-create the unit file according to LSB Header.
Start Filebeat:
user@tux ~ $ sudo service filebeat status
user@tux ~ $ sudo service filebeat start
We cannot provide filebeat options and arguments by /etc/init.d/filebeat script. Alternatively, we can manually start the service:
# run in foreground with '-e' option
user@tux ~ $ sudo /usr/bin/filebeat -e -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat/
user@tux ~ $ sudo /path/to/filebeat -e -c /path/to/filebeat.yml
# run in background; enable 'NOPASSWD:' or use '-b' option
user@tux ~ $ nohup sudo -b ./filebeat -c apple/filebeat.yml > logs/nohup.out 2>&1 &
user@tux ~ $ sudo -b nohup ./filebeat -c apple/filebeat.yml > logs/nohup.out 2>&1 &
-
The order of 'sudo' and 'nohup' does not matter in terms of 'SIGHUP'
But it makes a difference which part the 'sudo' is applied to.
-
The
-eoption is useful for debugging in that it logs to STDERR and disables syslog/file output.
Stop Filebeat
- If Filebeat is launched as a system service, stop it via the system service management functionality.
- If Filebeat is invoked in the console, stop it by
Ctrl-cor 'SIGTERM' signal.
Filebeat Processors
The libbeat library provides processors for:
- reducing the number of exported fields;
- enhancing events with additional metadata;
- performing additional processing and decoding.
For example, to drop messages beginning with 'DBG:':
processors:
- drop_event:
when:
regex:
message: '^DBG:'
A processor consists of a name, an optional when condition and a set of parameters:
processors:
- <processor_name>:
when:
<condition>
<parameters>
- <processor_name>:
when:
<condition>
<parameters>
- 'processor_name' is a one of the pre-defined processor name.
- when is a filter condition.
- 'when' and 'parameters' must be defined under the namespace of 'processor_name' which is a list item. The abbreviated form is
- <processor_name>: {when: {<condition>},<parameters>}. Consequently, they are indented further compared with 'processor_name'.- It a list item.
- The item value is a dictionary 'key: value' pair.
- The value of the pair comprises lists and dictionaries.
Processors are applied in the order they are defined and are valid at different levels:
- At the top-level (root level) in 'filebeat.yml' for all collected events;
- Under a specific input applied only to that particular input. When to drop universal fields (i.e. 'agent' and 'ecs'), 'drop_fields' should be defined in the top level.
Decode Json
If a log entry is in Json format, Filebeat will escape the Json object like this:
{ "outer": "value", "inner": "{\"data\": \"value\"}" }
From the sample outpout, the field 'inner' has a Json object escaped. To decode a Json field, means removing the escaping behaviour.
Here is a hands-on schema on how to correctly decode collected Json logs under the field of 'message':
- type: log
# ...
exclude_files: ['.gz$','~$']
json.keys_under_root: true
json.overwrite_keys: false
json.message_key: "host" # apply line and multiline filtering in accord with the specified Json key
include_lines: ['www.example.com']
exclude_lines: ['shit']
# ...
processors:
- decode_json_fields:
fields: ["message"]
process_array: false
max_depth: 1
target: ""
overwrite_keys: false
- drop_fields:
fields: ['@timestamp', '@metadata', "log", "tags", "input", "ecs", "host", "agent", "message"]
- Json Decoding can be configured at either 'inputs' level or 'processors' level.
- Regarding per-input level, as long as any one of the 'json.keys_under_root', 'json.overwrite_keys' and 'json.message_key' directives appear, Json decoding is applied.
- 'json.keys_under_root' places the decode Json at the root level.
- Decoded 'key: value' pairs will overwrite built-in pairs that share the same key if 'json.overwrite_keys' is enabled.
-
Json decoding happens before line (i.e. 'exclude_lines') filtering and multiline filtering. Hence, line and multiline filtering does not affect the original Json event as it is transformed.
The 'json.message_key' specifies a decoded Json key and applies line and multiline filtering to the event according the key value.
- 'decode_json_fields' is a global processor that applies to all inputs, with the 'fields' directive pointing to event fileds that require Json decoding.
- 'target: ""' is equivalent to 'json.keys_under_root'.
- 'overwrite_keys' and 'json.overwrite_keys' are equivalent as well.
-
'@metadata' and '@timestamp' cannot be dropped even they appear in in the list. Filebeat requires '@metadata' when sending out events (i.e. to Logstash).
A particular setup flow is like 'Filebeat - Kafka - Logstash'. We filter out the two fields in Logstash.
- IMPORTANT: Filebeat refuses to launch on some systems when either 'overwrite_keys' or 'json.overwrite_keys' is enabled. Check issue 6381 and issue 1378. Therefore, it is recommended to leave those two directives disabled.